

LLM 의 시작점: Attention is All You Need
LLM은 인코더와 디코더가 시작점이다.
나온 순서: ML (머신러닝)→ DL(딥러닝)→ LLM
LLM의 종류
Closed Source LLM(폐쇄형 LLM)
모델의 소스 코드 및 학습 데이터가 공개되지 않는다. API를 통해서만 접근 가능하고, 직접 모델을 수정하거나 재학습할 수 없다.
일반적으로 기업에서 개발하고 상업적으로 운영된다. 강력한 성능을 제공하나, 비용이 발생할 수 있다.
- OpenAI의 GPT-4, Google의 Gemini, Anthropic의 Claude, Mistral의 Mixtral
Open LLM
소스코드와 학습된 모델 가중치가 공개된다. 연구자나 개발자가 자유롭게 모델을 활용하고, 로컬 환경에서 실행하거나 추가 훈련이 가능하다. 오픈소스 커뮤니티의 기여로 지속적인 발전이 이뤄졌다.
- Meta의 LLaMA, Mistral, Falcon, BLOOM 등
LLM을 활용하기 위한 Prompt의 필요성
프롬프트는 LLM에게 주어지는 입력 문장으로, 모델이 어떤 방식으로 응답할지를 결정하는 중요한 요소이다.
프롬프트에 입력된 문장 = 사용자의 의도를 모델이 이해하고, 적절한 응답을 생성하도록 유도한다. 질문의 방식에 따라 답변의 질과 정확도가 달라진다.
인공지능의 궁극적인 목적: 사람의 일을 대신 하는 것
LLM의 구조: 디코더와 인코더

LLM은 Transormer 구조를 기반으로 하며, 주로 다음 세가지 아키텍처 중 하나로 구성된다.
- 인코더 기반 모델
- 디코더 기반 모델
- 인코더 - 디코더 기반 모델
1. 인코더 기반 모델
구조 및 특징
인코더는 입력 텍스트를 이해하고 문맥 정보를 학습하는 역할을 한다.
문장을 양방향으로 처리하여, 문맥을 더 깊이 파악할 수 있다.
주로 문장 분류, 개체명 인식, 감정 분석, 정보 검색 등 입력을 이해하는 작업에 활용된다.
작동 방식
- 입력 문장을 토큰(Token)으로 변환한다.
- 인코더가 문맥을 이해하며 각 단어의 의미를 벡터로 변환한다.
- 벡터를 기반으로 문장 또는 단어 수준의 예측을 수행한다.
EX) 입력: 나는 {MASK}를 좋아해. → 출력: 나는 “축구” 를 좋아해.
- 대표적인 인코더 모델인 BERT는 문장 전체를 보고 MASK 부분을 예측하는 방식으로 학습된다.
2. 디코더 기반 모델
구조 및 특징
디코더는 왼쪽에서 오른쪽(Left to Right)로 문장을 생성하는 역할을 한다.
이전 단어를 기반으로 다음 단어를 예측하는 오토레그레시브 방식으로 작동한다.
주로 텍스트 생성, 문서 요약, 챗봇 등에 활용된다.
작동 방식
- 입력 문장의 일부(프롬프트)를 토큰으로 변환한다.
- 디코더가 한 번에 하나의 단어를 예측해 문장을 생성한다.
- 이전에 생성된 단어를 참고해 반복적으로 예측한다.
EX) 입력: “오늘 날씨는” → 출력: “오늘 날씨는 맑고 따뜻합니다.”
- GPT 같은 디코더 기반 모델은 앞 단어를 기반으로 자연스러운 문장을 생성한다.
3. 인코더 - 디코더 기반 모델
구조 및 특징
인코더는 입력을 이해하고, 디코더는 새로운 문장을 생성한다.
입력과 출력을 모두 고려하는 작업을(번역, 요약) 을 한다.
작동 방식
- 인코더: 입력 문장을 벡터로 변환해 핵심 정보를 추출한다.
- 디코더: 변환된 정보를 바탕으로 새로운 문장을 생성한다.
EX) 입력: “Hello! How are You!” → 출력: 안녕하세요. 어떻게 지내시나요
- Bart, T5 같은 모델은 문맥을 이해하면서 새로운 텍스트를 생성할 수 있다.
LLM(말하기) 모델은 이미 말하기 위해서 여러 대량의 데이터를 학습했었다. Closed 모델이라 안 보이는 것 뿐…
Vector DB
Vector DB → LLM이 이해할 수 있도록 인코딩을 시켜줘서 벡터 디비라고 부름. 벡터 디비는 사람이 구축한다. 하지만 LLM이 사용한다.

벡터 디비에서 중요한 것: chunks
원본 벡터를 chunk로 자른 뒤, 각각의 chunk에 대한 representative code를 만들어 각 chunk에 대한 representation을 간단하게 한다. 그리고 나서 모든 chunks 를 합친다.

RAG
이 Vector DB를 활용해서 RAG(검색증강을 수행한다.
⇒ RAG 를 위해 Vector DB를 활용하고, 이를 참조하고 구축하는 과정을 RAG 파이프라인이라고 한다.
Tool calling
LLM은 기본적으로 과거의 데이터에 기반해 있어 현재의 정보를 요청한다면 거부한다. 그렇기 때문에 LLM이 현재 정보를 추가 확보할 수 있는 방법이 필요하다.
예시를 들어보자, 현재 주가를 확인할 수 있는 파이썬 툴인 yfinance가 있다. LLM에게 이러한 주가확인 툴이 있다고 알려주면 툴을 사용하게 된다.
이렇게 된다면 우리가 원하는 답변을 얻을 수 있는데, LLM에게 어떤 도구가 있는지를 알려줘서 해당 도구를 사용할 수 있도록 만드는것이 바로 tool calling이다.
LLM은 기본적으로 Text을 받아, Text를 반환하는 함수이다. LLM은 직접 함수를 실행시킬 수 있는 기능은 없다. 하지만 LLM은 어떤 함수를 어떻게 호출해야 하는지를 추론할 수 있다.

LLM이 함수를 활용해서, 아래 문장을 통해 어떤 함수를 호출하면 될지 추론(Reasoning)하도록 만들면 된다.
Langchain Tool
→ 이를 위해서 랭체인에서 Langchain Tool이 존재한다. LLM에게 먼저 함수에 대해 구체적으로 설명이 필요하다.
from langchain.tools import tool
@tool(parse_docstring=True)
def query_stock_price(ticker:str, date: str, field: str):이렇게 선언한 함수는 LLM이 이해할 수 있는 형태로 바뀌었고, 해당 함수에서는 해당 코드가 어떤 동작을 하는지, 어떤 파라미터를 받는지가 명세되어있다. 이후 LLM은 이 정보를 바탕으로 함수를 어떻게 호출하면 되는지 파악할 수 있다.
tools = [query_stock_price]
tool_llm = llm.bind_tools(tools)
tool_llm.invoke("명령") //체인 연결 그리고 LLM에게 bind_tools를 해 해당 도구가 있다는 것을 알려준다.
LLM 구조 이해하기
트랜스포머 이전 자연어 처리: Word Embedding
자연어를 모델에 입력하기 위한 임베딩이 연구되었다.
- Dense Vector: 0을 거의 안 쓰는 것?
유사한 단어들을 계속 벡터화 하는 것은 한계가 있었다.
Word Embedding의 한계점
- 동음 이의어 처리 불가
- 오타 및 새로운 단어 처리 불가
맥락의 등장
하지만 우리는 skool이라고 오타가 나도 school의 오탈자라는 것을 맥락을 통해 알 수 있다. 따라서 텍스트의 의미는 단어의 구성과 주변 맥락을 파악해야 알 수 있다는 것이 연구되었다.
트랜스포머 이전 자연어 처리: RNN
Recurrent Neural Network: 기억 장치(은닉값)이 있는 딥러닝 네트워크

인코더: 입력 문장의 은닉 값을 계산한다.
- Context Vector : 문맥 벡터도 저장한다.
디코더: Context Vector를 받아 목표 문장 생성
하지만 문장이 길어질 경우 뒤에있는 단어나 오래된 정보보다는 가까이에 있는 단어가 훨씬 효율적이므로 Context Vector도 한계가 있었다..
- 50단어로 이루어진 경우, 첫 단어를 잊는다.
여기서 Attention이 나오게 된다.
Attention의 등장
만약 디코더가 Mincho라는 단어를 출력해야 하는 상황이라면,

h1,h2,h3,C 중에서 디코더의 상태가 어떤 벡터와 가장 가까울까?
- C만 고려할 것이 아니라, h3과 같은 중간 상태에 집중해야 했다.
Transformer: 병렬 처리의 등장
RNN은 시간 순서대로 오기 때문에 은닉 계층에서 오는 전 정보들은 버렸었다. 하지만 그냥 통 벡터값을 쓰면 어떨까라는 병렬처리를 생각해오게 되었다.

순서대로 입력이 아닌 각자 들어가는 구조로, 토큰 개수만큼의 벡터가 인코더에서 생성되어졌다.
Transformer
자연어 처리에서 RNN이나 LSTM을 대체한 모델
- BERT, GPT의 근본이 되는 기본 아키텍쳐
- Self- Attention 매커니즘을 도입해 긴 문맥을 효율적으로 처리해 NLP Task 성능을 크게 향상함
Attention
디코더에서 출력단어를 예측하는 매 시점마다 인코더의 전체 입력 문장을 다시 한 번 참고한다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중해서 보게 된다.
입력 시퀀스의 각 요소가 다른 요소와 얼마나 중요한지, 어느 부분에 집중할지를 결정하는 매커니즘이다.
어텐션 함수
어텐션 함수는 주어진 쿼리에 대해서 모든 키와의 유사도를 각각 구한다. 그리고 구해낸 이 유사도를 키와 맵핑되어있는 각각의 값에 반영해준다. 그리고 유사도가 반영된 값을 모두 더해서 리턴한다. 여기서는 이를 어텐션 값이라고 한다.
Q = Query : t 시점의 디코더 셀에서의 은닉 상태
K = Keys : 모든 시점의 인코더 셀의 은닉 상태들
V = Values : 모든 시점의 인코더 셀의 은닉 상태들
attention 시에 Query, Key, Value를 한 번에 던진다.

EX) “The animal didn’t cross the street because it was too tired.”
|
Query
|
해당 단어가 다른 단어들과 얼마나 연관이 있는지를 묻는 값
|
ex) <it>은 무엇을 가리키고 있나요?
|
|
Key
|
각 단어가 어떤 의미를 가지고 있는지 나타내는 값
|
ex) 나는 “animal”이야. 나는 “street” 이야.
|
|
Value
|
해당 단어의 실제 의미를 나타내는 값
|
ex) 자기소개를 듣고 유사도를 계산한다. it ↔ animal 유사도 높음 it ↔ animal 유사도 낮음
|
MultiHead-attention

각각 다른 QKV 쌍을 통해 여러 질문을 던지고, 그 결과를 모두 모아서 집중해야 하는 단어를 정확하게 찾아내기 위한 방식이다.
Head: 여러 개의 Attention 매커니즘이 동시에 작동
Multi-Head: 여러 헤드가 동시에 작동해 문장의 의미를 더 풍부하고 정확하게 이해할 수 있도록 한다.
self - attention

다른 단어와 나의 관계가 어떤 관계인가를 학습한다.
입력된 문장 내 다른 단어들과 얼마나 관련있는지를 계산해 문맥을 더 잘 이해하도록 하는 것이다.
다른 표현: ‘이 문장에서 이 단어는 어떤 의미인가?’ − “나는” = “나는 밥을 먹었다“ 에서의 “나는” − “밥을” = “나는 밥을 먹었다“ 에서의 “밥을” − “먹었다” = “나는 밥을 먹었다“ 에서의 “먹었다”
Mask
→ 특정 데이터를 가리거나 보이지 않도록 설정하는 기법이다.
→ LLM이나 딥러닝 모델에서 특정 정보를 차단하고 가리기 위해 사용된다.
시계열 데이터(시간 흐름에 따라 순서대로 발생하는 데이터) 는 순서대로 발생하니까 내가 판단하는 시점에서는 내 앞에 있는 것 밖에 모른다.
Masking 적용 예시
아래와 같이 5개의 시간 단계(time step)를 가진 시계열 데이터가 있다고 가정하자.
|
시점
|
데이터
|
|
1
|
10
|
|
2
|
12
|
|
3
|
15
|
|
4
|
18
|
|
5
|
20
|
우리는 3번 시점에서 예측할 때, 4번과 5번 데이터를 알면 안 됨.
따라서, 미래 데이터에 Mask를 적용하여 모델이 접근하지 못하게 막아야 함.
✅ 올바른 예측 방식 (Mask 적용됨)
- 1 → 2 → 3까지만 보고 4를 예측
- 1 → 2 → 3 → 4까지만 보고 5를 예측
❌ 잘못된 방식 (Mask 적용되지 않음, 미래 정보 사용)
- 1 → 2 → 3 → 4를 보고 3을 예측 (데이터 누수)
Positional Encoding
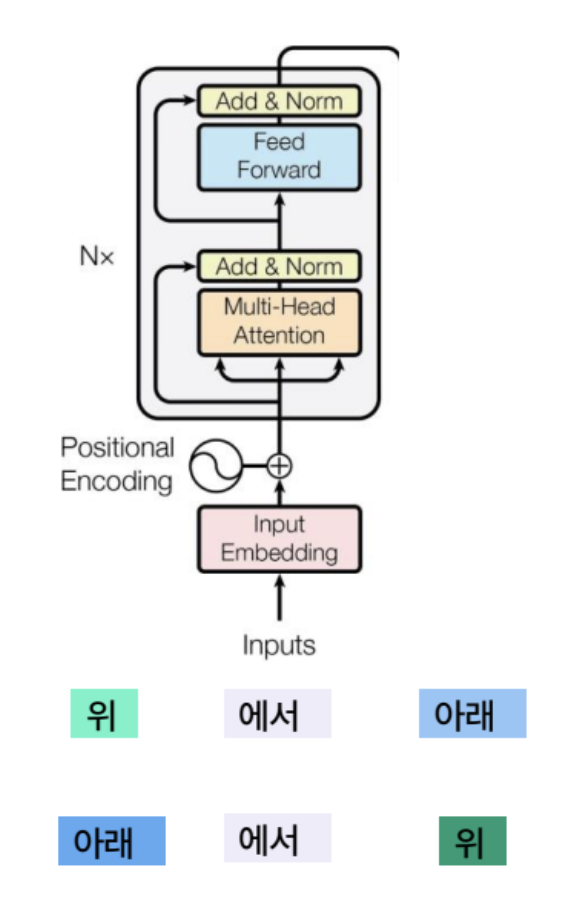
위에서 아래와 아래에서 위는 다른 의미이지만, 토큰 임베딩만으로만 구별이 불가능했다.
이를 보완하기 위해, 위치 인코딩 벡터를 정의했다.
- 몇번째 단어인지 의미하는 벡터값
- 단어 임베딩 + 위치 인코딩의 결과를 인코더, 디코더에 전달한다.
Encoder 구조

inputs: 입력 문장 단어 목록
Outputs: 입력 문장의 단어별 의미 벡터
Decoder 구조

Input : 입력 문장의 단어별 의미 벡터와 문장 일부 (Ex: <BOS> I had) Output: 새로운 토큰 (Ex: meal)
디코딩: 순차적 추론
디코딩은 확률이다. (0과 1사이)
디코딩의 output 과정
- Last Hidden State가 Token의 확률로 변환
- Greedy: 단순히 Max_prob 선택하기(직관적이나 최적은 아닐 수 있다.)
- Beam Search: Next Token 선택 + 전체 확률을 계산해 상위 K개의 후보만 계속 전진하는 구조
- Top - K : 확률 순 상위 K개의 토큰에서 샘플링(소프트맥스)
- Top -P: 확률 순 토큰의 누적합이 P를 넘지않은 분포에서 샘플링

RNN처럼 순서대로 나는→밥을→먹었다가 아닌, 나는,밥을,먹었다가 모두 간다.

생성형 AI의 가장 중요한 요소중 하나가 파인튜닝
- Encoder-Decoder Attention
Transformer 모델 종류

BERT
Transformer의 인코더 기반의 양방향(Bidirectional Encoder) 모델이다. 양방향이니만큼 입력 문장의 앞 뒤 문맥을 모두 고려해 단어를 이해하는데 중점을 둔다.
Pre-training Model: 버트는 대량의 데이터로 언어의 규칙과 의미를 학습한 사전 모델이다.
파인튜닝: 사전 학습된 버트를 특정한 작업에 맞게 추가 학습 하는 것이다.
BERT 에서의 Masking(양방향 모델)
버트는 양방향 모델로, 문장 전체를 보고 특정 단어를 예측할 수 있다.
예시로,
입력문장으로 "나는 [MASK]를 좋아해.” 가 들어오면,
출력 예측으로 "나는 축구를 좋아해." 처럼 예측할 수가 있다.
양방향 모델이니 만큼 나는 과 좋아해 를 보고 예측한다.
GPT
Transformer의 디코더 기반의 Autoregressive 모델이다.
Autoregressive: 데이터 시퀀스에서 이전 값을 기반으로 다음 값을 예측하는 모델

GPT의 Masking(시계열과 유사)

GPT의 Masking (Auto-Regressive, 시계열과 유사)
GPT는 이전 단어만 보고 다음 단어를 예측하는 모델이다. 즉,미래 단어를 보지 못하도록 Masking이 적용된다.
예시로,
입력: "나는 오늘"
출력: "나는 오늘 피자를 먹었다."
GPT 모델은 "나는"을 보고 "오늘"을 예측하고, "나는 오늘"을 보고 "피자를"을 예측하는 방식으로 진행된다.
뒤에 있는 단어는 미리 보이지 않도록 Masking 처리된다.

Context Length

LLM의 미래 : GPT5? AGI? 확률론적 앵무새를 벗어나보겠다
Agent
주어진 환경에서 특정 목표를 수행하는 자율적인 시스템을 의미한다.
컴퓨터 과학, AI, LLM 등 다양한 분야에서 사용된다.
LLM (Large Language Model)에서의 Agent
LLM 기반 Agent의 역할
- LLM 자체도 일종의 Agent처럼 동작하지만, 더 발전된 개념으로 Agent 시스템을 활용하여 LLM이 다양한 작업을 수행하도록 설계할 수 있다.
- Agent는 LLM과 외부 도구(API, DB, 검색 엔진 등)를 연결하여 더 강력한 기능을 수행할 수 있다.
LLM 기반 Agent의 예시
- 자동 문서 요약 Agent
- 검색 기반 Agent
- 코드 작성 및 실행 Agent
- Task Automation Agent
LLM Agent의 동작 방식
- 사용자 입력 (Prompt) 수신
- 질문 분석 및 의사 결정
- 필요한 도구(API, 데이터베이스, 계산기 등) 활용
- 결과를 정리하여 출력
예시: 검색 기반 LLM Agent
- 사용자가 "올해 월드컵 결승전 날짜가 언제야?"라고 물어봄
- LLM은 이 질문을 분석하고, 최신 정보를 위해 웹 검색 API를 호출
- 검색 결과를 분석한 후, 사용자에게 최종 답변을 제공
실습
워드 임베딩
query = '문서 인식 인공지능' //쿼리를 던짐
target_texts = {
"업스테이지, 차세대 OCR모델 '다큐먼트 파서' 공개...현존하는 가장 우수한 AI 문서처리",
"구글, AI 이미지 생성 모델 '이마젠 3' 전면 무료화... '제미나이'에서 누구나 사용 가능",
"세계 최고 성능의 온디바이스 AI 구현... 미스트랄, 엣지 모델 '미니스트랄 3B와 '미니스트랄 8B' 발표",
"거래소, 제3회 KRX 금융 언어 모델 경진대회 개최",
}
#네개 문장의 임베딩 생성
response_candidates = client.embeddings.create(
input = target_texts,
model = "text-embedding-3-large"
)
target_embeds = [record.embedding for record in response_candidates.data] # 4개의 임베딩 저장
target_embeds = np.array(target_embeds).astype("float32")Open AI 어시스턴트 API 써보기
openAI 어시스턴트는 검색, 함수 호출, 코딩 등의 기능을 더 잘 활용하는 API 기능이다. 작동하는 방식은 GPTs나 에이전트와 유사하다.

어시스턴트
LLM + tool 이 결합된 객체
어시스턴트 생성
- name: 어시스턴트의 이름
- instructions: 어시스턴트의 행동 지침을 결정
- tools: 어떤 기능을 활용할지 결정
math_assistant = client.beta.assistants.create(
name = "수학 선생님",
instructions = "이 문제룰 풀기 위한 수학적인 배경 지식을 먼저 알려주세요. 파이썬 코드를 사용해 주어진 문제를 해결하고, 풀이과정을 자세히 설명하세요..",
tools = [{"type": "code_interpreter"}],
model ="gpt-4o",
temperature=0.2
)어시스턴트는 id를 통해 다른 객체와 연결된다.
math_assistant.id쓰레드
메세지가 순차적으로 저장되는 공간(chatGPT의 채팅방과 유사)
하나의 쓰레드는 하나의 대화를 의미한다.
쓰레드에 메세지를 추가해 원하는 형태의 대화를 수행할 수 있다.
쓰레드 생성
def create_thread(message):
thread = client.beta.threads.create(
message = [{"role":"user", "content":message}]
)
return thread
#파라미터로 메세지를 받아서 쓰레드를 리턴한다.런
어시스턴트와 스레드를 연결해서 작동시키는 객체. 런이 만들어져야 어시스턴트가 스레드에 응답을 한다.
런 스텝
런이 실행될 때마다, 메세지와 툴 사용을 구분해 중간 결과를 저장한다.
쓰레드와 어시스턴트 연결
Thread와 assistant id를 연결하는 방법은 run 객체를 생성하는 것이다.
런 객체를 생성하면, Open AI의 서버 큐에 전달되고 이때 런의 상태는 queued가 된다.

- Single-Turn: 질문을 하면 해당 질문만 참고해서 LLM이 답변하는 것
- Muilti-Turn: 질문을 하면 이전 질의(질문 및 응답) 내용을 모두 참고하여 LLM이 답변하는 것
token → 어차피 내가 요청한 처리의 단위(과금단위)
LLM이 처리할때→ 내부적으로 주고받는 그릇 크기인코딩할 때 인코딩 시킨 벡터
좋은 모델일 수록 적은 수의 그릇으로 빨리 처리한다.
자신만의 AI Agent 만들기
환경 설정
!pip install crewai==0.28.8 crewai_tools==0.1.6 langchain_community==0.0.29
!pip install openai==1.55.3 httpx==0.27.2# Warning control
import warnings
warnings.filterwarnings('ignore')from crewai import Agent, Task, CrewCrew AI
Crew AI를 이용해 AI agent를 통해 복잡한 작업을 손쉽게 처리할 수 있는 프레임워크이다.
Crew 생성
Agent
에이전트는 CrewAI에서 작업을 수행하는 주체이다. 이들은 특정 작업을 수행하도록 프로그래밍된 자율적인 AI이다.
|
role
|
이 에이전트가 수행하는 역할
|
|
goal
|
에이전트가 목표로 해야할 일
|
|
backstory
|
에이전트가 해야 하는 일의 배경 설명
|
bazi_analyzer = Agent(
role="사주 해석가",
goal="사용자의 사주팔자를 해석하고, 성향 및 운세를 분석",
backstory="당신은 사용자의 사주팔자를 분석하여 오행의 균형, "
"성향, 적성, 대운 및 세운을 해석하는 일을 합니다.",
allow_delegation=False,
verbose=True
)Tools
툴은 에이전트가 테스크를 수행하는데 사용되는 도구이다. 소프트웨어, API, 데이터베이스 등 다양한 형태를 가질 수 있다.
Task
태스크는 에이전트가 수행해야 할 구체적인 과제나 작업이다. 이는 작업의 세부사항, 수행 방법, 필요한 도구 등을 포함한다.
bazi = Task(
description =(
"{dateOfBirth} {timeOfBirth}에 대해 사주 팔자를 분석하고, "
"음양력 변환 및 천간 지지, 오행 요소를 계산한다."
),
expected_output ="사주 팔자 분석 결과",
agent = bazi_generator, #task를 수행할 agent
)Crew
Crew는 여러 Agent와 Task를 조직적으로 관리하는 역할을 한다. 이 프로젝트에서는 3개의 Agent와 3개의 Task를 Crew에 등록해, 순차적으로 실행되도록 설정한다.
Crew의 역할
- 각 Task를 올바른 순서로 실행 (Task 실행 흐름 관리)
- 에이전트 간 협업 조정 (각 Task를 수행할 적절한 Agent 연결)
- 입력값을 전달하고 최종 결과를 반환
crew = Crew(
agents=[bazi_generator, bazi_analyzer, fortune_advisor],
tasks=[bazi_task, fortune_analysis_task, fortune_advice_task],
verbose=2 # 실행 과정에서 상세 로그 출력
)크루들 일 시작! = kickoff()
result = crew.kickoff(inputs={"dateOfBirth":"2001.01.01"});
print(result)전체 프로세스

사용자의 생년월일 입력 → 사주 생성 task → 사주 분석 task → 개인 맞춤 조언 task
출처: KataCoder LLM Agent 개발하기 (2) Tool Calling, SKALA 자료,https://www.sktenterprise.com/bizInsight/blogDetail/dev/11315
'SKALA' 카테고리의 다른 글
| [SKALA] 2일차: LLM 모델의 이해 및 활용 (1) | 2025.02.04 |
|---|